
ユーザーが欲しいものに見合った技術を選びローコストで自然言語処理AIを導入できた話
ディップでは「バイトル」「バイトルNEXT」「バイトルPro」などの求人サイトを展開しています。それらの媒体に掲載する求人原稿の作成を誰でもできるようにするために「GENKO」というツールの開発を行いました。
GENKOは、求人原稿のレコメンド機能等の点で利用者から好評を得ていましたが、レコメンドされる文章の種類を増やしてほしいなどの更なる要望も上がっておりました。そこで追加開発されたのがAIを用いた文章レコメンド機能です。過去の文章データから類似した文章をテンプレートとして提示するAIの開発によりGENKOのレコメンド機能はより幅広いものへと進化したそうです。今回はそのプロジェクトにおいてAIのモデル構築を担当した藤本に話を聞きました。
過去のデータを活用して文章レコメンドの幅を広げたい
――導入前の状況・課題について教えてください。
GENKOは経験の有無にかかわらず「誰でもバイトルの求人広告が作れる」をコンセプトに開発されたプロダクトです。GENKOには原稿文言のレコメンド機能があるのですが、今までは広告制作部があらかじめ用意していた文言をロジックで組み合わせるしくみになっていて、バリエーションが乏しいという問題がありました。
――今回の開発が始まった経緯について教えてください。
原稿文言のレコメンド機能自体はとても好評だったので、データサイエンスの技術で先述の課題を解決してほしいとの依頼を受け、プロジェクトがスタートしました。
類似文も検索結果に含めることでより検索意図にあった結果を
――どのような方針で改善をしていきましたか。
AIによって原稿文言自体を生成するのは難易度が高いので、まずは書きたい文章に近い過去の原稿を検索できる機能を作りました。
――過去の原稿検索をするにあたってポイントになったところはどこですか。
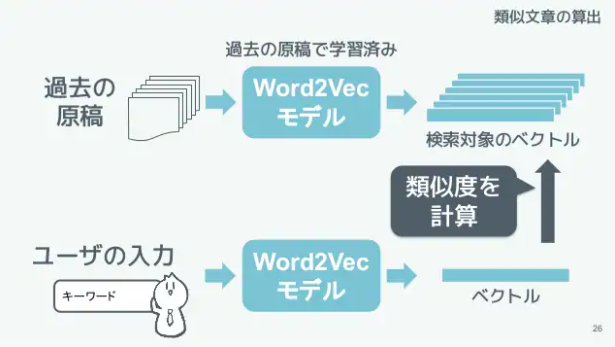
過去の原稿検索機能においては、Word2Vecという自然言語処理の手法を使いました。Word2Vecは単語をベクトルで表現する手法で、単語の意味を定量的に表現することができます。そして、このベクトル同士の類似度を計算することで似た単語を抽出できます。
これを用いて、ただキーワードが含まれる文章を抜き出してくるだけではなく、近い意味の言葉も検索できるように開発を進めていきました。
Word2Vecによる類似単語検索の仕組み(新卒2ヶ月でAIを社会実装させた3つのデザインより)
スクラム体制と並行したAI実装
――どのような体制で取り組みましたか。
「年4835時間の削減を見込む、スクラム体制で作り上げた求人原稿作成支援ツール GENKO 開発の裏側」で紹介されているように、GENKOプロジェクト自体はスクラム体制でプロジェクトは進んでいますが、それと並行して、私がデータ分析や機械学習モデルの実装をし、原稿の質を上げる施策を行っています。
――プロジェクト推進体制のよかったところを教えてください
インフラ側の知識など自分の理解が進んでいない部分も、スクラムマスターの宗里さんがサポートしてくださいました。そして、フロントエンジニアやデザイナーの方々もアドバイスくださるので、開発チームで円滑なコミュニケーションを取りながら進めていくことができました
固有表現をマスキングすることで過去の文章をテンプレート化
――本取り組みで困難だったことについて教えて下さい。
類似する単語を含む過去の文章を検索結果として提示することは高い精度で実現できました。しかし、過去の文章をそのまま提示しても、汎用性が低いため原稿作成者にとっては使いづらいです。
この問題を解決するために、過去の文章をテンプレート化する必要があったのですが、大量に存在する過去の原稿をテンプレート化するためにどうしようか悩みました。
――どのようにその問題を乗り越えましたか。
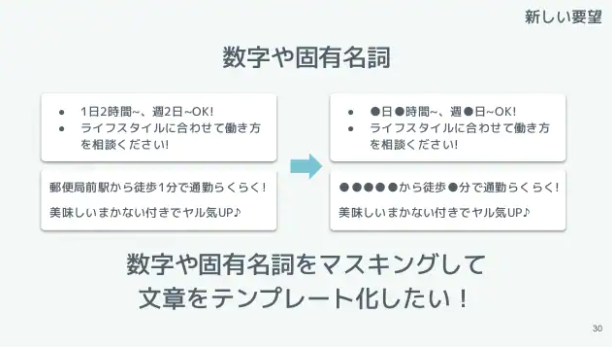
過去の文章の汎用性が低いのは、会社名や地名などの固有名詞、「徒歩1分」などの数字の部分の影響が大きいです。
ですので、これらの固有名詞や数字をマスキングできれば、過去の文章をテンプレートとして活用しやすくなると考えました。
固有名詞や数字をマスキング(新卒2ヶ月でAIを社会実装させた3つのデザインより)
GiNZAという固有表現抽出ライブラリを用いることで、それらの表現を一挙に抽出することが可能になり、既存の文章のテンプレート化を実現できました。
ユーザーが欲しいものに見合った技術を選べば、ユーザー体験の向上と開発運用コストの低減を両立できる
――どのように課題が解決されましたか。
以前は職種ごとにテンプレートの文章が用意されているだけでしたが、過去の文章を検索できるようにすることで今までよりも、書きたい内容により近い文章が見つけられるようになりました。
――今回のプロジェクトのやりがいを教えてください。
今回の施策では、AIを用いたシステムの導入をスモールスタートで実践することができたため、これからの施策にもつながるとても良い経験でした。
使っている技術は、特に新しいものではなく、モデルの作成も容易です。
ユーザーが本当に欲しい機能は何かということを考えたうえで、それを実現するために適切な手法を選定することで、ユーザー体験の向上と開発運用コストの低減を両立できました。
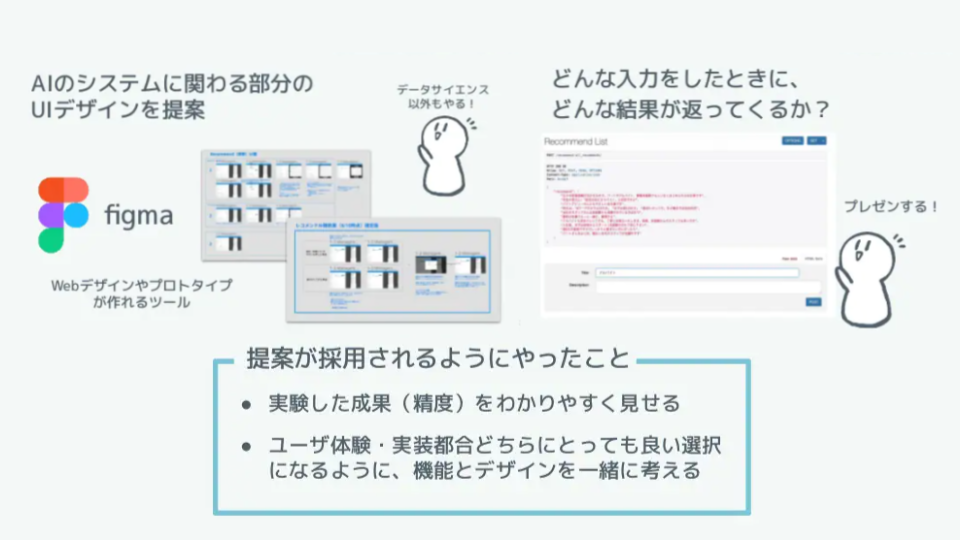
また、導入するシステムをプロダクトオーナーチームに提案するところも、良い勉強になりました。システムの機能面の話だけではなく、どのようなUIデザインで実装するかという提案を入れたり、デモ画面を作成して実際に使ってもらうことで、共通のイメージを持って議論することができました。そのおかげで、速く開発を進めることができました。
デモ作成やデザインにより素早い開発を実現(新卒2ヶ月でAIを社会実装させた3つのデザインより、DX magzine編集部一部改変)
今後も自然言語処理を使って更なる改善に取り組みたい
――今後取り組みたい改善はありますか。
今回のGENKO改善はこれで終わりではなく、これからもさらにデータを活用した改善を展開していきたいです。
文章のレコメンドに関しては、どのようなキーワードが検索されているかのデータを取得しつつ、検索の精度や検索のしやすさを向上させるための施策を考えています。また、誤字や禁止文言、不足要件の抽出を行って、書いた原稿を添削する機能などのシステムを導入して、文章の質の向上を目指したいです。
――Data Brain課の中で今後取り組みたいことはありますか。
GENKOはもちろん、整理されていない社内ナレッジの抽出や、マーケティングの施策などに取り組んでいきたいと思っています。ですが、自然言語を扱う分析者が足りていないため、自然言語処理に取り組んでみたいという仲間をもっと集めることも同時に進めていきたいです。
――ありがとうございました!
DX人材積極採用中!
ディップではDX人材を積極採用中です。DXプロジェクトを推進してみたい方、ぜひ一度カジュアルにお話してみませんか?
『3000人超の従業員の業務を支えるディップの社内ITカオスマップ』ではディップの社内IT環境と、募集している職種について記載しています。ぜひご覧ください。




